

Googleフォームを用いて、アンケート調査が気軽に行えるようになってはいますが「1,000件を超えるアンケートの自由記述読んでいる時間がない……」 「なんとなく『満足』が多い気もするけど、具体的に何が受けているのか客観的に示したい」。そんな思いを抱く方も多いのではないでしょうか。
業務でアンケートを実施した後、一番の宝の山でありながら、一番処理が面倒なのが「自由記述(テキストデータ)」ですよね。
今回は、Googleスプレッドシートに溜まった回答を、Linux Mint上のPythonを使ってサクッと「ワードクラウド(頻出単語の可視化)」にする方法について見ていきたいと思います。
Googleドキュメントのデータ分析
さて、最近のGoogleのAI機能の進化は凄まじく、Google スプレッドシートの「Gemini」メニュー>「データを分析する」でグラフの生成、洞察をしてくれるようになっています。
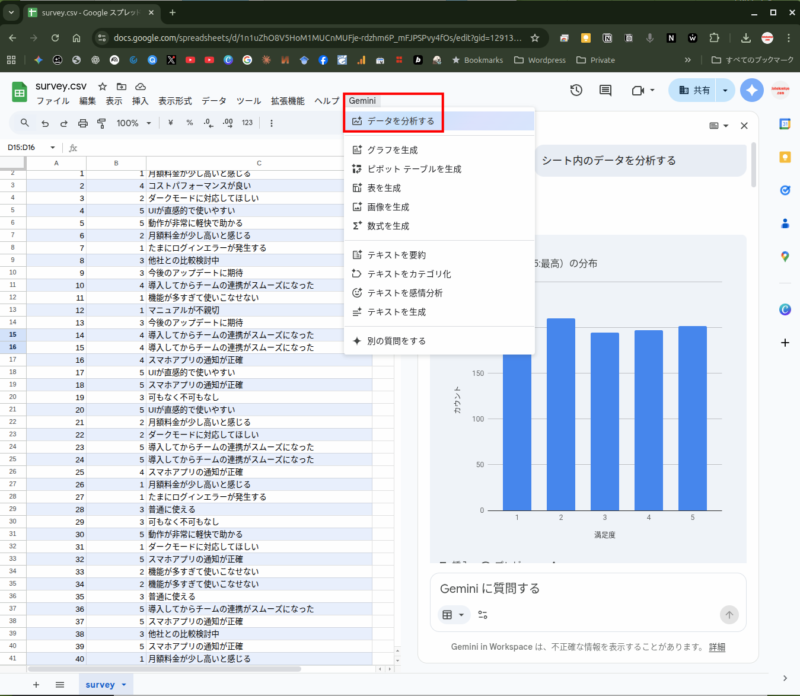
これだけでもかなり有益なのですが、自由記述について、さらに詳細な分析を行っていきたいと思います。
Linux MintとPythonでのテキストマイニングです。
1. 準備するもの:Linux Mintなら一瞬で揃います
Windowsだと環境構築でつまずきがちなPythonなのですが、Linux Mintなら標準でインストールされています。
このPythonによって、OSを”汚すことなく保護する”ために仮想環境によって作業部屋を作って作業することができます
ツールは一つ一つ「ソフトウェアマネージャー」でインストールすることもできるのですが、そこはLinuxのいいところ。次のコマンドを端末(ターミナル)でコピペするだけ(ミドルクリックペーストがオススメ)で速攻で環境を整えられます。
1,必要なツールのインストール
sudo apt update
sudo apt install python3-pip python3-full2,仮想環境(analysis_env)の作成
cd ~
python3 -m venv analysis_envこれにより新たにホームディレクトリの中に「analysis_env」というディレクトリが作成されます。この中で全ての作業がOSに影響を与えることなる行われます。
この中に「survey.csv」という名前でスプレッドシートをカンマ区切り形式(.csv)でダウンロードしておきます。
以上で下準備は完了です。
2,テキストマイニングを行うためのコードをAIで生成
コードを自分で書くのは大変です。書いているうちに日が暮れます。
AIにサクッと記述してもらいます。
まずは、Geminiに集計済みのスプレッドシートをアップし、どんなプロンプトにすればいいかを尋ねます。
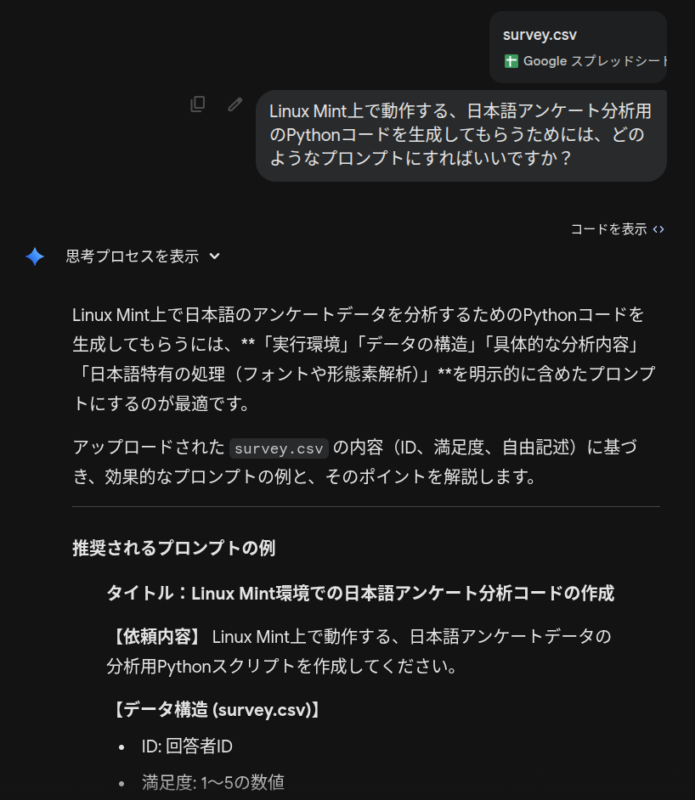
回答として、必要なライブラリーのインストールと、日本語が正常に表示されるようにフォントの追加について提案されました。
システムの日本語フォントをインストール(インストール済みでもちゃんとスルーしてくれます)
sudo apt update
sudo apt install fonts-ipaexfontPythonライブラリのインストール
pip install pandas matplotlib janome wordcloudちなみにそれぞれのライブラリの役割は次の通りです。
- pandas: データの表計算用
- matplotlib:グラフを描画
- janome: 日本語をバラバラに分解する(形態素解析)
- wordcloud: 単語を雲のような画像にする
そして、今回生成してもらったPythonのコードは次の通りです。
import pandas as pd
import matplotlib.pyplot as plt
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
from collections import Counter
import os
# --- 設定 ---
INPUT_FILE = 'survey.csv' # アップロードされたファイル名に合わせて変更してください
FONT_PATH = '/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf'
# Linux Mint標準のIPAexGothic
# Matplotlibの日本語フォント設定
plt.rcParams['font.family'] = 'IPAexg'
def load_data(file_path):
"""エンコーディングを考慮してCSVを読み込む"""
encodings = ['utf-8', 'cp932', 'utf-8-sig', 'euc-jp']
for enc in encodings:
try:
df = pd.read_csv(file_path, encoding=enc)
print(f"Successfully loaded with encoding: {enc}")
return df
except UnicodeDecodeError:
continue
raise ValueError("CSVファイルの読み込みに失敗しました。文字コードを確認してください。")
def analyze_satisfaction(df):
"""満足度の基本統計量と分布の可視化"""
print("\n--- 満足度の基本統計量 ---")
print(df['満足度'].describe())
# 棒グラフの作成
counts = df['満足度'].value_counts().sort_index()
counts.plot(kind='bar', color='skyblue', edgecolor='black')
plt.title('満足度の分布')
plt.xlabel('満足度 (1-5)')
plt.ylabel('回答数')
plt.xticks(rotation=0)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.savefig('satisfaction_distribution.png')
print("満足度の分布グラフを 'satisfaction_distribution.png' として保存しました。")
plt.close()
def analyze_text(df):
"""自由記述の形態素解析とワードクラウド生成"""
t = Tokenizer()
words = []
print("\nテキスト分析中...")
for text in df['自由記述'].dropna():
tokens = t.tokenize(text)
for token in tokens:
# 名詞または形容詞のみを抽出(記号や助詞を除外)
part_of_speech = token.part_of_speech.split(',')[0]
if part_of_speech in ['名詞', '形容詞']:
# 「する」「ある」などの一般的すぎる語を除外(必要に応じて追加)
if len(token.surface) > 1:
words.append(token.surface)
# ワードクラウドの作成
if not words:
print("有効な単語が見つかりませんでした。")
return
text_content = " ".join(words)
wordcloud = WordCloud(
font_path=FONT_PATH,
background_color='white',
width=800,
height=600,
colormap='viridis'
).generate(text_content)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('自由記述のワードクラウド')
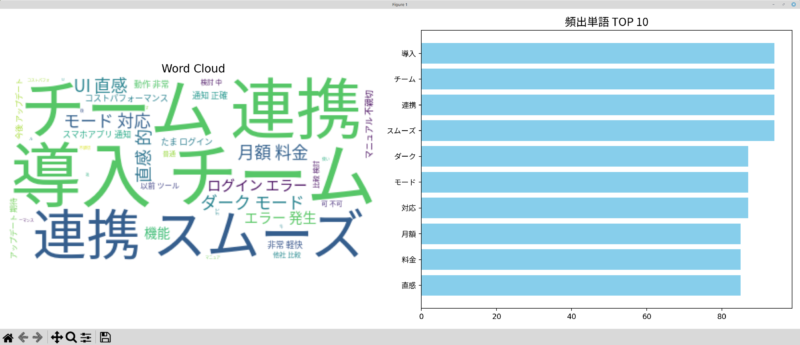
plt.savefig('wordcloud.png')
print("ワードクラウドを 'wordcloud.png' として保存しました。")
plt.close()
# 頻出単語トップ10を表示
print("\n--- 頻出単語トップ10 ---")
counter = Counter(words)
for word, count in counter.most_common(10):
print(f"{word}: {count}回")
def main():
if not os.path.exists(INPUT_FILE):
print(f"エラー: {INPUT_FILE} が見つかりません。")
return
# 1. データ読み込み
df = load_data(INPUT_FILE)
# 2. 数値分析
if '満足度' in df.columns:
analyze_satisfaction(df)
else:
print("警告: '満足度' 列が見つかりません。")
# 3. テキスト分析 & 可視化
if '自由記述' in df.columns:
analyze_text(df)
else:
print("警告: '自由記述' 列が見つかりません。")
if __name__ == "__main__":
main()「analysis_env」ファルダー内の空きスペース上で右クリック>「新しいドキュメントの作成」>「空のドキュメント」を選択
ファイル名を「analyze.py」に変更して、さらにダブルクリックでテキストエディタで開いて、AIが生成してくれた上記のコードをコピペして保存しておきます。
同じディレクトリ内で、右クリック>「端末で開く」を選んで端末を起動。
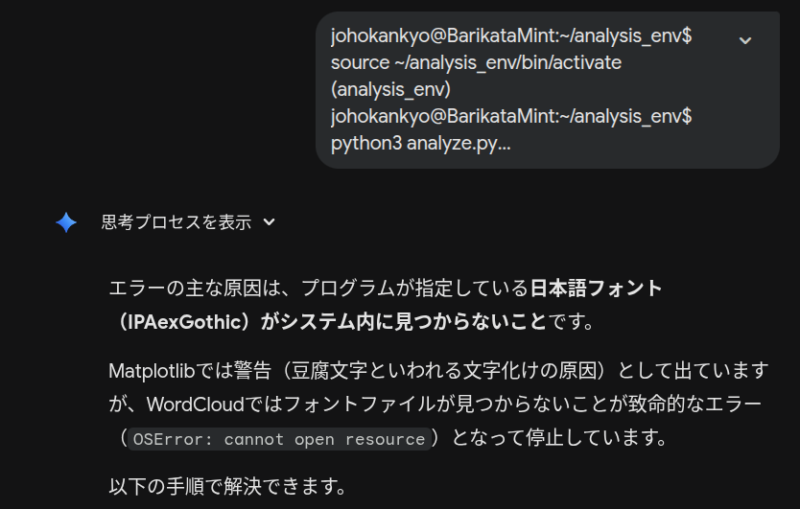
★重要:仮想環境の「有効化」:これを実行すると、行の先頭に (analysis_env) と表示されます
source ~/analysis_env/bin/activate
それではいよいよ、次のコマンドで実行します。
python3 analyze.pyエラー発生!助けてGemini!!
エラーが発生してしまった場合、端末内のに記述されているものを丸ごとコピーして、Geminiのプロンプト欄に丸ごと貼り付けてエンターすれば、修正点を教えてくれます。
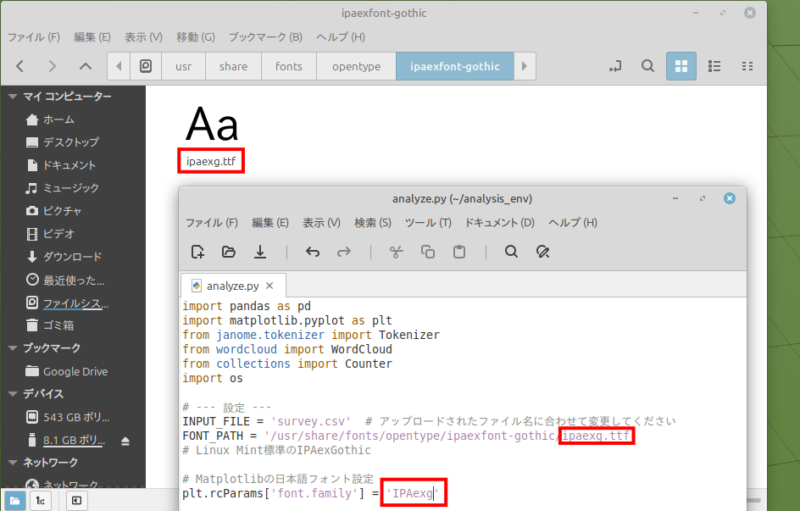
今回の場合、コード内に記されたフォント名が正確でなかったのが原因でした。
フォント名を正しく変更します。
改めて再度実行
気を取り直して、改めて次のコマンドで実行します。
python3 analyze.pyすると、一瞬で作業ディレクトリの中に図が生成されます。
今回AIが指定してくれたように日本語フォントを追加しないと、日本語の文字が”豆腐”状態となってしまいます。
その辺りもGeminiはきちんと把握してくれていました。偉いですね!
まとめ:OSSはビジネスの武器になる
今回使ったツールはすべて無料のオープンソースです。
Linux Mintなら、こうしたツールがOSの深いところで安定して動作してくれます。
「手作業で3時間かかる集計が、スクリプト一つで3秒で終わる」
この快感を一度味わうと、もう元の環境には戻れないかもしれません。
johokankyo.comでは、これからもあなたの「情報環境」をより良くするOSS活用術をお届けしていければと思っております。









コメント