
中国製のコスパのいいMiniPCをすでに5台購入している中で、2024年9月に購入したRyzen9 6900HX, RAM:32GBの機種をローカルAI用として活用しています。OSはLinuxMint 22.1です。
メモリーが32GBありRyzen9の高性能CPUということで、7B~14Bクラスの高性能モデルをローカルで動かすことができているのですが、余っているグラフィックスボードの有効活用ということで、さらにGPUを活用することで高速化を図ります。
このMini PCにはOculinkのポートがあり、手持ちのグラフィックスボード”GeForce RTX4060″を利用できるようにします。
NVIDIAのドライバーとCUDA Toolkitの追加インストール
GeForce RTX 4060の性能をローカルAIで最大限に活用するためには、NVIDIAのドライバーとCUDA Toolkitの追加インストールが必須となりますが、正しく設定することでとても強力なローカルAI環境を構築することができます。
CUDAをインストールする意味
今回使用するMin PCの頭脳(CPU)はAMD製ですが、ローカルAIの計算を爆速化してくれる腕力(GPU)としてNVIDIA製のRTX 4060を追加する、という構成です。
AIソフトウェア(Ollama, LM Studioなど)がNVIDIAのGPUに計算を命令するためには、両者の間に「通訳」が必要です。この通訳の役割を果たすのが以下の2つです。
- NVIDIA ドライバー: OS(Linux)がRTX 4060というハードウェアを正しく認識し、制御するための基本的なソフトウェアです。
- CUDA Toolkit: AIの計算(専門的には並列計算)の命令を、ドライバーを通じてGPUに伝達するためのライブラリや開発ツールのセットです。
これらをインストールしないと、AIソフトウェアは高性能なRTX 4060の存在に気づけず、計算はすべてCPU(Ryzen 9 6900HX)で行われてしまいます。せっかくのグラフィックスボードが無駄になってしまうため、設定は不可欠なものとなります。
LinuxMintでの設定手順
ステップ1: eGPUの物理接続と認識確認
まず、PCの電源がオフの状態でOCuLink経由でRTX 4060を接続し、電源を入れます。 Linuxが起動したら、ターミナルを開いて以下のコマンドを実行し、システムがNVIDIAのカードをハードウェアとして認識しているか確認します。
lspci | grep -i nvidiaこのコマンドで、NVIDIA Corporation を含む行が表示されれば、ハードウェアとしては正しく認識されています。
ステップ2: NVIDIAドライバーのインストール
次にドライバーをインストールします。ターミナルで以下のコマンドを実行します。
これにより、ハードウェアに最適な推奨ドライバーが自動でインストールされます。
sudo ubuntu-drivers autoinstallインストールが完了したら、必ずPCを再起動します。
ステップ3: CUDA Toolkitのインストール
ドライバーのインストール後、CUDA Toolkitをインストールします。これもUbuntu系のパッケージマネージャー(apt)からインストールするのが簡単です。
sudo apt update
sudo apt install nvidia-cuda-toolkitこれにより、AIソフトウェアが必要とするCUDAのライブラリなどがシステムに導入されます。
ステップ4: 最終確認(最重要)
すべてのインストールと再起動が完了したら、ターミナルで以下のコマンドを実行します。
nvidia-smiこのコマンドで以下のような情報が表示されれば、セットアップは完璧です。
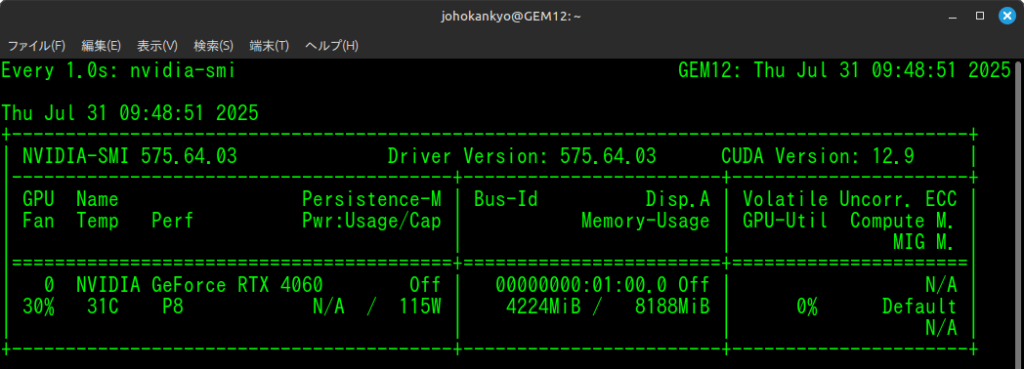
確認すべきポイント
- GPU Name: 「NVIDIA GeForce RTX 4060」と表示されていること。
- Driver Version: ドライバーのバージョンが表示されていること。
- CUDA Version: CUDAのバージョンが表示されていること。
この画面が表示されて、Linux PCはRTX 4060をAIのために使う準備が整いました。
あとは、OllamaやLM Studioなどのツールを用いてローカルAIを利用します。
GPUが使われているか確認する
次のコマンドでGPUの稼働状況を1秒ごとに更新して表示してくれます。
watch -n 1 nvidia-smi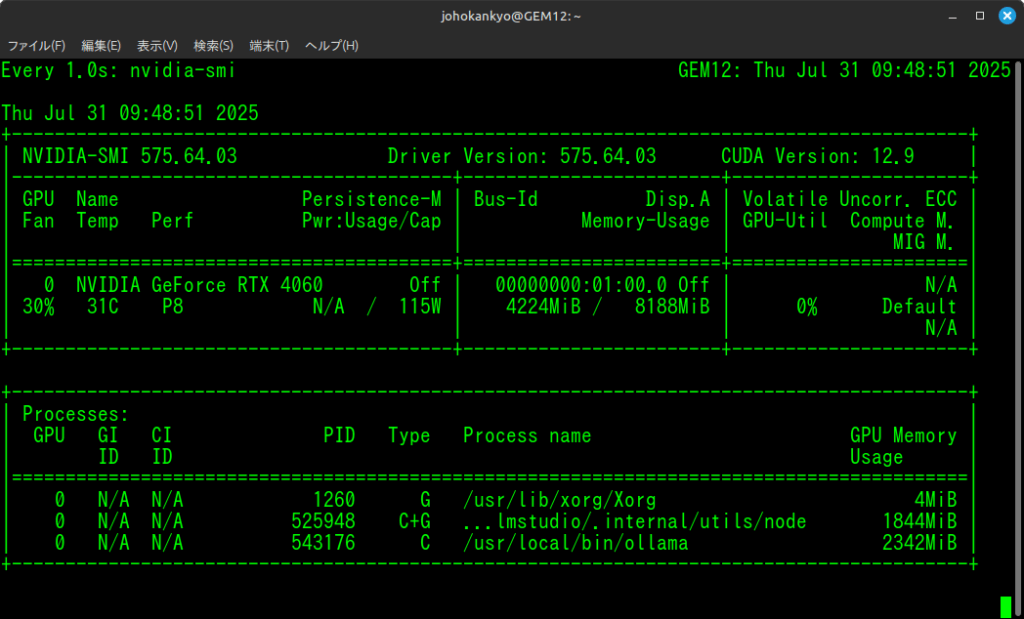
この画像の例では、8GB搭載されているVRAMを、LM Stuidoで約1.8GB, Ollamaで約2.3GB使用してしている状況を示しています。
これにより、GPUが正しく稼働していることがわかります。
LM StudioでGPUの負担割合を調整
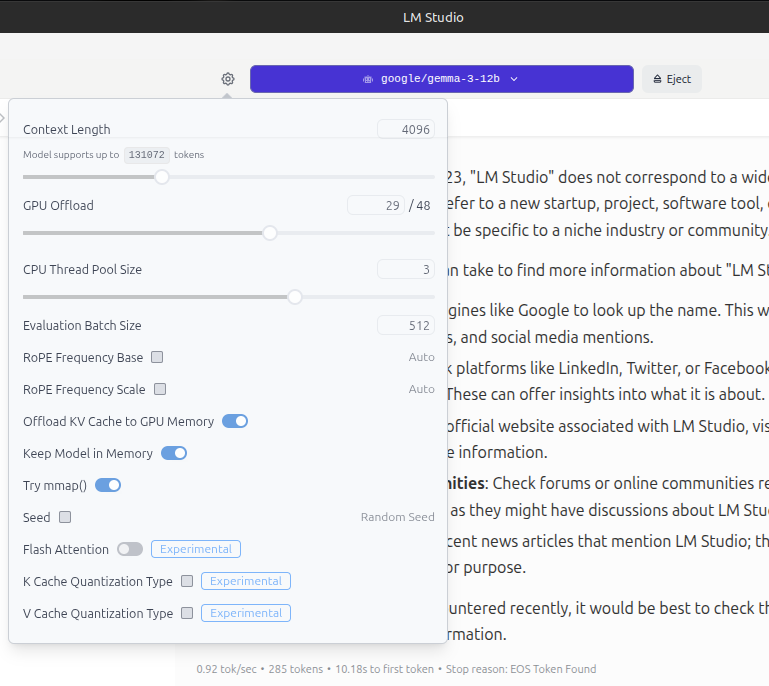
LM Studioでは、GPUの負担する割合を調整することができます。
LM Studioの上部の青紫のバーにAIモデル名が表示される左横のギアアイコンをクリック
「GPU Offload」の数値を大きくすることで、GPUの負担を高めることになります。
以上で、体感的にかなりローカルAIのレスポンスが速くなりました。
今回使用した機材

AOOSTAR MiniPC
AMD ryzen9 6900hx(8コア/16スレッド、周波数3.3GHz-4.9GHz)プロセッサー、AMD Radeon 680M 12コア RDNA3グラフィックス、zen3+ GPUアーキテクチャ。GEM12シリーズMINI PCはデュアルメモリチャンネルにアップグレードした。大容量デュアルDDR5(16Gx2)4800HMzメモリ、1TB充実したストレージ搭載され、二つM.2 2280 NVME PCle 4.0x 4スロットは最大4TBx2拡張できます。WIFI6/Bluetooth5.2対応、USB4 x1 Oculink x1 USB3.2 Gen 2(10GPBS)x2 USB2.0 x2 LAN(2.5G)x2 3.5mm音声 x1 DP1.4 x1 フル機能 Type-C x1 HDMI2.1 x1豊富インサーフェス搭載
アマゾンで当時割引で63,980円という格安で購入しました。

MINISFORUM DEG1 外付けGPU ドッキングステーション Oculink対応
アマゾンで当時12,000円ほどで購入

ちなみにMini PCとGPUとの接続はOculinkケーブル1本でつなぐだけです。
画像出力についてはMiniPC本体のHDMIケーブルでモニターに接続することで、画面表示を行います。
さいごに
まずは手持ちの機材でLinuxMintの環境で、Nvidiaドライバー、CUDA Toolkitを導入することでローカルAIをレスポンス良く利用できる環境の構築が可能であることが、改めて確認できました。
Intel Core i5/7の第8世代以降、PCのマシンスペックにはほとんど気にせずに来たのですが、久しぶりに高性能なマシンスペックを追い求めることになりそうで、ヤバいです。







コメント