

2024年9月に購入したAOOSTARのミニPC GEM12でローカルAIを毎日のように使い続けてきたら、頻繁に電源切れを起こすようになってしまいました。小さな筐体で高性能なCPUを用いる場合、「排熱」をしっかりしないとダメですね・・・ということで、新たに購入したのは排熱がしっかりしてそうなGMKtec Nucbox M7。一世代前の機種なんですが、かなりお買い得だったので購入。
Windows 11 Proがプリインストールされており、これを消してしまうのももったいないので、SSD M.2の空きスロットにGEM12のSSD 1TBを装着して Linux Mintとのデュアルブートにしました。
RAMもGEM12の32GB(DDR5)を付け替えて、引き続きローカルAIを持ち運びできるようにしていきます。
なぜAI開発にはLinuxが好まれるのか?
WindowsでもAIは動きます。でも、世界の最先端を行く開発者たちはLinuxを使います。なぜでしょうか?
- AIの公用語が動く: AI開発の主要言語「Python」や、主要ライブラリはLinuxファーストで作られています。
- GPUを直接叩ける: Windowsの分厚い壁(OSの管理層)を通さず、よりダイレクトにハードウェアの性能を引き出せます。
- Dockerが速い: 仮想環境を作る「Docker」が、Linuxならネイティブで動くため高速で軽量です。
つまり、「同じハードウェアでも、Linuxの方がAIのフルパワーを引き出しやすい」のではないか?と思っています。
それにしても残念なAOOSTARのミニPC GEM12
このミニPC、Ryzen9 6900HXを搭載した高性能な機種なのですが、使用中に頻繁に電源が落ちる現象はおそらく「電力供給不足」(一時的な電圧低下)あるいは「排熱の問題」だと思われます。

消費電力・発熱量=TDPを抑えて運用すればいいと思われるのですが、残念ながらこの機種のBIOS設定ではTDP設定の変更の項目が見当たらず、どうしようもなくGMKtec Nucbox M7に買い替えた次第です。
内蔵GPU「Radeon 680M」の底力
GEM12同様GMKtec Nucbox M7にもOculinkポートが搭載されており、事務所では外付けグラフィックスボードGeForce 4060と接続しながら使用します。出先では内蔵のRadeon 680Mで使用することになります。
AIを動かすには、CPUだけでなく「GPU(グラフィックス処理装置)」の性能が重要で、一般的にAIにはNVIDIA製の大型グラフィックボードが必要と言われていますが、このRadeon 680Mでもそこそこストレスなく利用可能です。
それでは端末で次のコマンドを叩いて、AMD GPUを認識させていきます。
sudo apt update
sudo apt install -y curl git build-essentialコンテナ技術「Docker」の導入
*以前、Python上でOllamaを動作させた模様を書きました。今回は、アプリを「コンテナ」という箱に閉じ込めて動かす技術である「Docker」で動かしていきます。
これを入れておくと、後で「AIのWeb操作画面(Open WebUI)」などを導入するときに、コマンド一発で環境が作れるようになります。現代エンジニアの必須科目とも言えるでしょう。
# Docker公式のインストールスクリプトをダウンロード&実行
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# 現在のユーザー(自分)がsudoなしでDockerを使えるようにする
sudo usermod -aG docker $USER
# 設定を反映させるため、一度ターミナルを閉じて、開き直すか、ログアウト&ログインする
# (ここでは一度PCを再起動するのが確実です!)#再起動後、以下のコマンドでバージョンが表示されれば成功です。
docker --version
「Ollama」のインストール
ローカルLLM(大規模言語モデル)を動かすために「Ollama(オラマ)」をセットアップします。
curl -fsSL https://ollama.com/install.sh | sh*ダウンロード&インストールが自動的に行われます。(数分かかります)
このツールのいいところは、AMD GPUを使うための面倒なドライバ設定(ROCmライブラリ)を、ある程度内包してくれている」点です。
Radeon 680Mを認識させる
Radeon 680Mに、「Radeon RX 6000シリーズ(RDNA2アーキテクチャ)と同じ仲間」と錯覚させる設定を行います。
ターミナルで以下のコマンドを実行し、Ollamaの設定ファイルを編集します。
sudo nano /etc/systemd/system/ollama.service以下のような画面が開いたら、[Service]セクションに下図のように一行追加します。
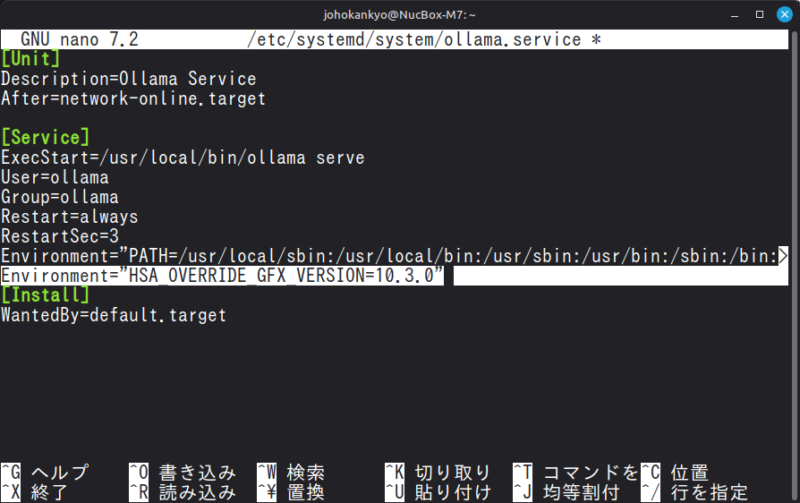
Environment="HSA_OVERRIDE_GFX_VERSION=10.3.0"書き足したら、
Ctrl + Oを押して、Enter「保存」。Ctrl + Xを押して「終了」します。
設定の反映と再起動
設定を読み込ませて、Ollamaを再起動します。
sudo systemctl daemon-reload
sudo systemctl restart ollamaAIとの対話
準備は整いました。実際にAIモデルをダウンロードして動かしてみます。
今回は、Googleによって作成されたモデル「Gemma3」でテストしてみます。
ターミナルで次のコマンドを打ち込みます。
ollama run gemma3
すると、数GBのモデルデータのダウンロードが始まります。ダウンロードが終わったら「>>>」というプロンプトが表示されるので、日本語で話しかけてみます。
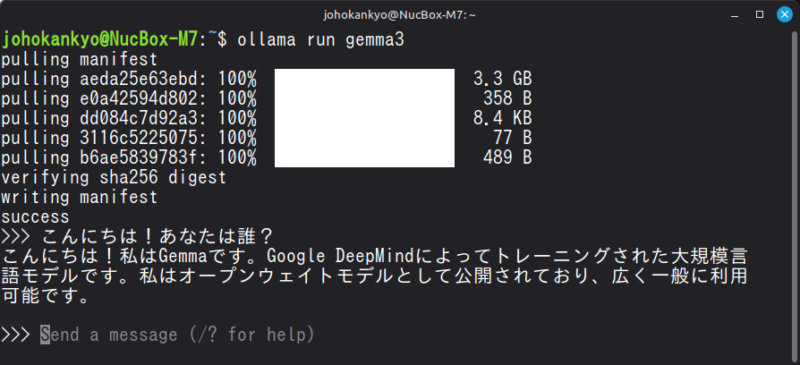
以上により、ミニPCという小さな箱の中でAIが動作し、インターネットがなくてもターミナルの中で動作する「ローカルAI環境」を手に入れることができました。
このように、ターミナル内でも充分に利用できるのですが、ChatGPTやGeminiのようにブラウザーで便利に使えるようにしていきます。
「Open WebUI」でChatGPTライクな環境を作る
「Open WebUI」というツールを使うと、Ollamaで動いているAIを、ブラウザ上のリッチな画面で操作できるようになります。見た目はほぼChatGPTやClaudeと同じ。しかも、高機能です。
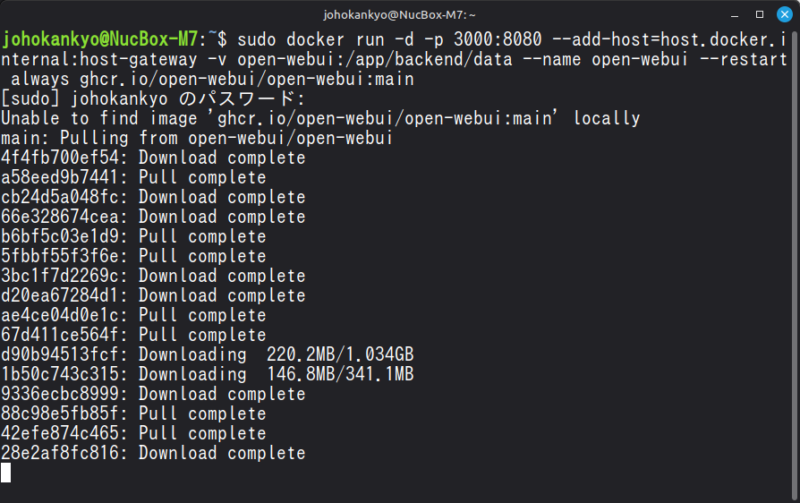
長いのですが、下記コマンドをターミナル上で実行することで、Dockerコンテナを立ち上げて、Ollamaと連携させることができます。
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main次のようにopen-webuiのサーバーが稼働し始めたらOKです。
ブラウザでアクセス
ChromeなどのWebブラウザを開いてアドレスバーで以下を入力します。
http://localhost:3000初期設定画面で管理者アカウントを作成します。
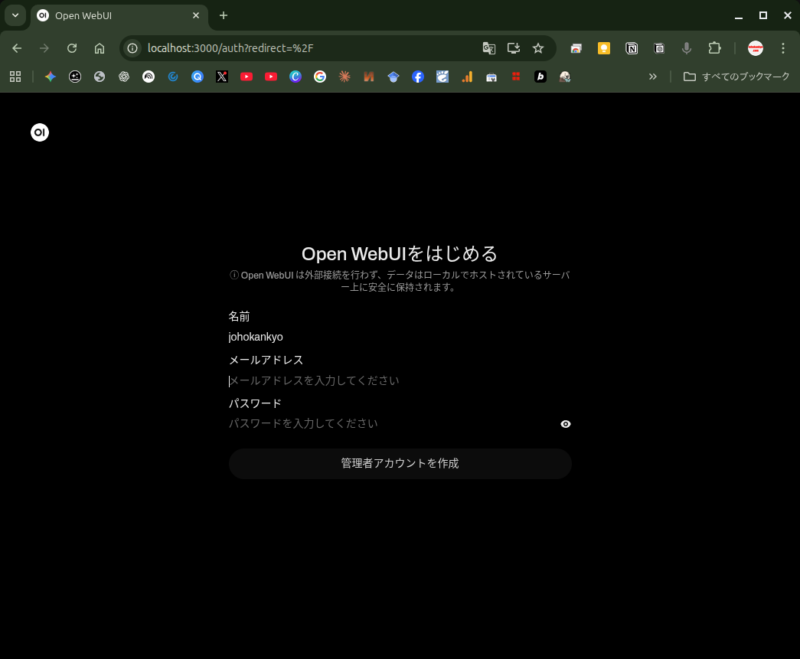
外部に送信されるわけではないので安心してください。
複数のモデルをダウンロードしておいて、切り替えながら利用ができます。
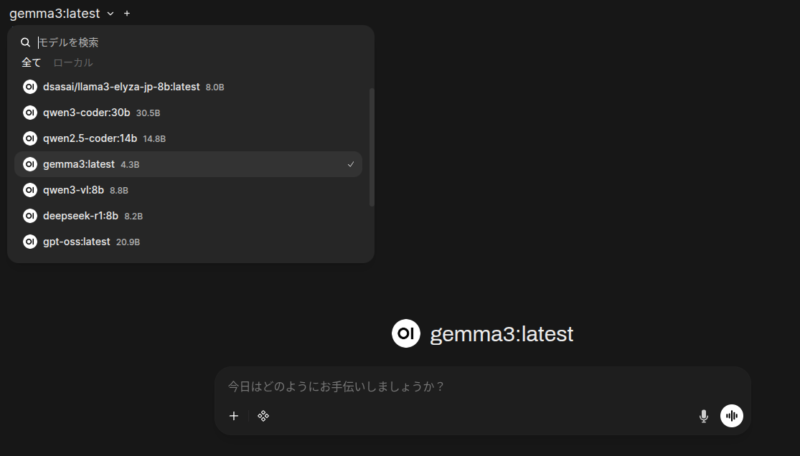
どのローカルLLMモデルを使う?
ローカルAIの最大のメリットは、「自分の目的に合わせて、脳みそ(モデル)を自由に取り替えられること」にあります。
- 小説を書きたいなら、創作が得意なモデル。
- プログラミングをするなら、コーディング特化モデル。
- 日本語で自然に会話したいなら、日本文化を学習したモデル。
RAM 32GBを搭載したミニPC 「GMKtec M7」でも使えるモデルを探していきたいと思います。
1. まず知っておくべき「サイズ」の話
モデル選びで一番重要なのは「パラメータ数(サイズ)」です。 モデル名の後ろについている 「8B」 や 「14B」 という数字がそれです。「B」はBillion(10億)を意味します。
今回の環境(RAM 32GB / Radeon 680M)での目安は以下の通りかな?と思います。
| サイズ表記 | イケてる度 | 特徴 | 動作感 |
|---|---|---|---|
| 1B 〜 3B | ◎ | 超軽量・爆速 | 一瞬で返答が来る。簡単なタスクや実験用に。 |
| 7B 〜 9B | ☆最適 | バランス最高 | 賢さと速度のバランスが良い。普段使いはここ! |
| 12B 〜 14B | ◯ | ちょっと重い | 少し生成に時間はかかるが、かなり賢い。論理的。 |
| 27B 〜 32B | △ | 限界挑戦 | 動くが遅い。RAM 32GBをフルに使う。じっくり長文を書かせる時などに。 |
| 70B以上 | × | 動作困難 | メモリ不足で動きません。 |
基本は「8B前後」で、ここぞという時には「14B〜32B」のモデルを試していこうと思います。
2,モデルの入手はOllama Libraryで
- ブラウザで Ollama Library にアクセスします。
- 「Popular(人気順)」や「Newest(新着順)」を見てみます。
- 気になったモデルをクリックすると、詳細ページに飛びます。
- 使いたいサイズのタグ(下記の例ではgemma3:12b)の右にあるコピーボタンを押します。
- ターミナルを開いて「ollama run」と入力したあとにペーストします。
ollama run gemma3:12b
ダウンロードが始まり、完了したら画面上部のモデル名表示部分をクリックしてモデルを切り替えます。
3,私の好みのモデル5選
Googleの叡智:gemma3:9b/12b
- 特徴:Googleが開発。9B(90億パラメータ)または12b(120億パラメータ)で、クラス上のモデルに匹敵する賢さを持ているそうです。論理的思考力が高く、クリエイティブな文章生成も得意。
- 用途: 原稿の執筆、アイデア出し、複雑な推論。
- 入手コマンド: ollama run gemma3:9b または ollama run gemma3:12b
OpenAI純正のオープンモデル:gpt-oss:20b
- 特徴: OpenAIが開発。「20b(200億パラメータ)」というサイズながら、内部はMoE(混合エキスパート)構成となっており、推論能力はかつてのGPT-4クラスに肉薄。
- 用途: 高度な論理推論、複雑なタスクの自律実行、商用アプリへの組み込み。
- 入手コマンド: ollama run gpt-oss:20b
世界の標準:llama3.1:8b
- 特徴:Meta社が公開した、オープンソースLLMの決定版にして「世界標準」の地位を確立したモデル。非常に長い論文やマニュアルも丸ごと読み込んで理解可能。
8BモデルはRAM 32GB環境では非常に軽快に動き、推論能力、多言語対応、ツール利用能力のバランスに優れる。 - 用途: 長文ドキュメントの要約・分析、チャットボットのベース、複雑な指示の実行。
- 入手コマンド: ollama run llama3.1:8b
日本語の達人:dsasai/llama3-elyza-jp-8b
- 特徴: 日本の企業Elyzaが、Llama 3をベースに徹底的に日本語を学習させたモデル。
日本の文化、敬語、独特の言い回しへの理解度が段違いです。
「関西弁で話して」などの無茶振りにも強い。 - 用途: 日本語での雑談、メールの作成、日本独自のトピック。
- 入手コマンド:ollama run dsasai/llama3-elyza-jp-8b
優秀なプログラマー:qwen2.5-coder:14b, qwen3-coder:30b
- 特徴: 中国Alibaba発ですが、今やコーディング能力では世界トップクラス。
PythonやJavaScriptなどのコードを書かせると、恐ろしいほどの精度を出してくれます。
14Bモデルなら、簡単なアプリの設計図も書いてくれます。qwen3-coderはさらに高度。 - 用途: プログラミング支援、バグ探し、技術的な質問。
- 入手コマンド: ollama run qwen2.5-coder:14b または ollama run qwen3-coder:30b
ファイルを読み込ませて「RAG」を体験
Open WebUIの凄いところは、「RAG(検索拡張生成)」機能が標準装備されている点です。
すなわち「手持ちの資料をAIに読ませて、それについて質問できる機能」です。
- チャット入力欄の左にある「+」ボタンを押します。
- 「Upload Files」を選び、PC内にある適当なPDF(マニュアルや論文、会議の議事録など)を選択します。
- アップロードが完了したら、そのファイルについて質問することができます。
この資料の要点を3つにまとめてください。数秒後、AIが資料の中身を読み解き、要約してくれます。
ネット上のChatGPTに社外秘のPDFをアップロードするのは躊躇しますが、この環境なら外部には一切漏れません。
これこそが、ローカルAI最大のメリットだなぁと思っています。
なぜLinux MintでローカルAI?
Windows版のOllamaもあるし、WSL2もあります。なぜわざわざSSDを増設してまでLinux MintでローカルAIを利用するのか?
実は、「ローカルAI」という特定の”競技”において、Linuxは「ドーピングなしで身体能力が高いアスリート」のような圧倒的なアドバンテージを持っています。
1. 【最大の理由】「VRAM(ビデオメモリ)」の空き容量が全然違う!
ローカルAIを動かす上で、最も貴重で、最も高価なリソースは「VRAM(ビデオメモリ)」です。 AIモデルはVRAMに展開されて計算を行います。VRAMが足りないと、遅いメインメモリを使ったり、そもそも起動しなかったりします。
Windowsの事情
Windowsは、美しいデスクトップ画面(ウィンドウの透明効果やアニメーション)を描画するために、何もしていなくても0.5GB〜1GB以上のVRAMを消費します。さらに、バックグラウンドで動く無数のサービスもメモリを食います。
Linux Mint (Cinnamon) の事情
一方、Linux Mint(特にCinnamon版やMATE版)は非常に省エネです。 デスクトップの描画に必要なVRAMはごくわずか。OS自体が消費するメインメモリも、起動直後なら1GB程度です。
結論: 「OSが使う分が少ない = AIに割り当てられるメモリが増える」 特にGMKtec M7のような「メインメモリをVRAMとして共有するミニPC」においては、OSが軽量であることは、そのまま「より賢い(大きな)AIモデルが動かせる」ことに直結します。これがLinuxを選ぶ最大の理由です。
2. AI開発の「ホームグラウンド」である
AI(機械学習)の世界は、基本的にLinuxファーストで動いています。
- Pythonライブラリ: PyTorchやTensorFlowなどの主要ライブラリは、Linux環境での動作が最も安定しており、最新機能がいち早く提供されています。
- AMD ROCm: 今回使用しているAMD GPU用の計算ライブラリ「ROCm」は、長らくLinux専用でした。Windows版も出てきましたが、まだ発展途上で制限が多い状況です。
WindowsでAIをやる場合、多くの設定で「Windows特有のつまづきポイント」に遭遇します。パスが通っていない、文字コードが違う、ドライバの仕様が違う…。
一方、Linux Mintなら、世界中の開発者が前提としている「標準的な環境」そのものです。教科書通りのコマンドがそのまま通る快適さは、一度味わうと戻れません。
3. 勝手な再起動やアップデートがない
長い時間をかけてAIに画像を生成させたり、モデルの学習(ファインチューニング)をさせたりしている最中に… 「Windows Updateのために再起動します」、、、という悲劇は以前と比べて減りはしましたが、余計なお世話な、迷惑なプロセスが裏で動いています。
Linux Mintは、ユーザーが許可しない限り勝手に再起動することはありません。アップデートのタイミングも完全にユーザーがコントロールできます。 「サーバー(奉仕者)」としてPCを使う場合、この実直な安定性は必須条件です。
4. Dockerコンテナが「ネイティブ」で爆速
「Docker」を使えば環境を素早く構築できるのですが、実はOSによって仕組みが違います。
- Windows (WSL2): Windowsの中で「小さなLinux仮想マシン」を立ち上げ、その中でDockerを動かしています。
オーバーヘッド(無駄な負荷)がかかりますし、ファイルアクセスが遅くなることがあります。 - Linux Mint: OSのカーネル(核)機能を直接使ってコンテナを動かすので、ネイティブに動作します。
オーバーヘッドがほぼゼロで、ハードウェアの性能をダイレクトに引き出せるということで、ミニPCのような限られたリソース環境では、この差が体感速度に効いてきます。




コメント